Benchmarks 1: disk.frame beats Dask! disk.frame beats JuliaDB! Anyone else wanna challenge?
ZJ
Source:vignettes/06-vs-dask-juliadb.Rmd
06-vs-dask-juliadb.RmdIntro - Benchmark 1
This is the first in a series to benchmark the performance of disk.frame vs other medium-data tools. For Python, we will benchmark Dask, and for Julia, we will benchmark JuliaDB.jl. In the process, I will do a warts-and-all account of the tools I have tested.
The title was ‘inspired’ by this post titled “R beats Python! R beats Julia! Anyone else wanna challenge R?”.
TL;DR
For this simple benchmark, disk.frame is faster. But Dask has a more convenient syntax. JuliaDB.jl is not ready for prime time.
Timings
Please note I have not tried to record the precise times over many runs, but I aim illustrate the magnitude of speed of the different packages
library(ggplot2)
df = data.frame(
tool = c("disk.frame", "Dask", "JuliaDB.jl"),
timing = c(17.9, 50, 76)
)
ggplot(df) +
geom_bar(aes(x = tool, weight = timing), stat = "count") +
ylab("seconds") +
ggtitle("Convert to desired format timing")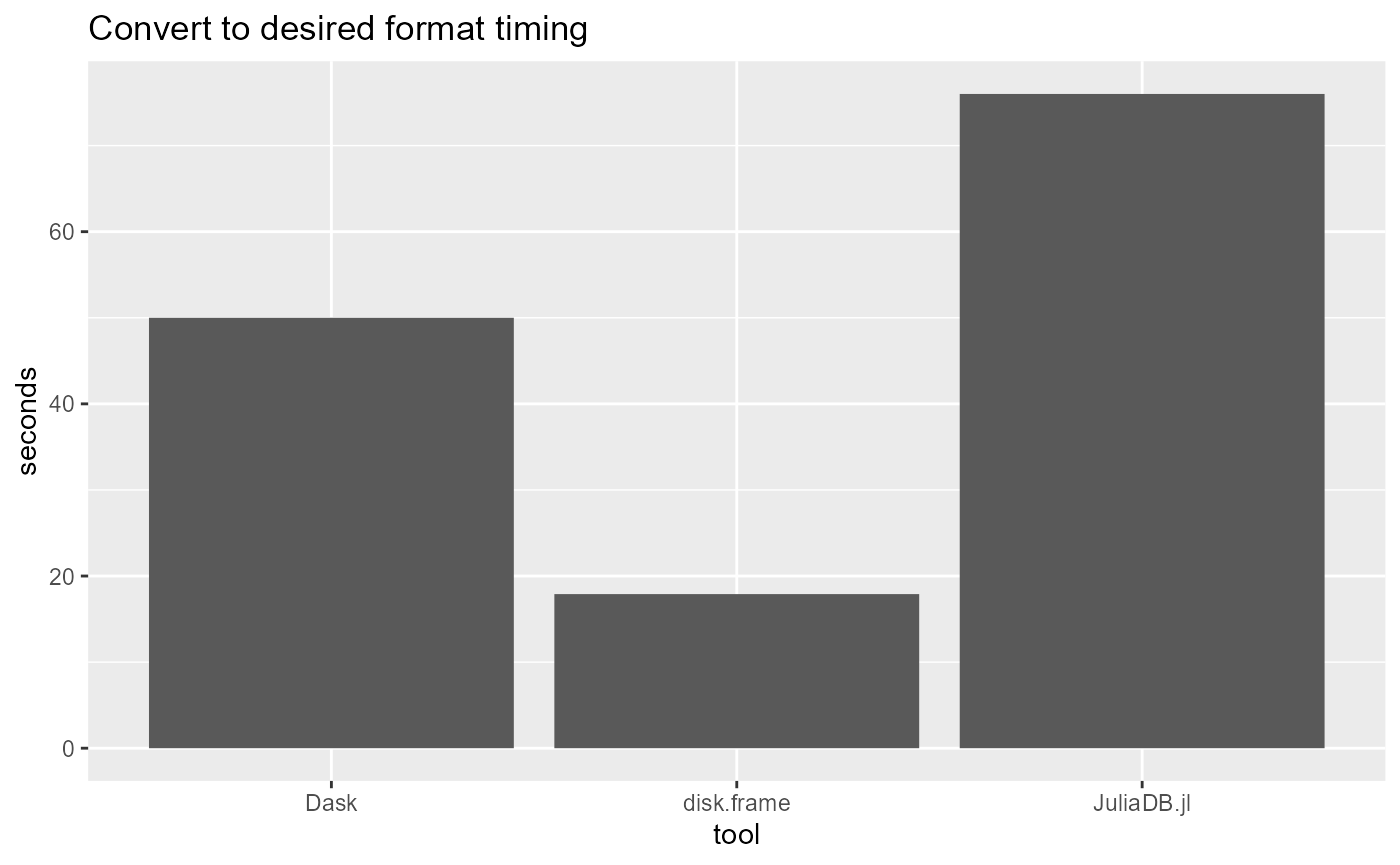
Next up is timings for the simple aggregation
df = data.frame(
tool = c("disk.frame", "Dask", "JuliaDB.jl"),
timing = c(1, 1.2, 6)
)
library(ggplot2)
ggplot(df) +
geom_bar(aes(x = tool, weight = timing), stat = "count") +
ylab("seconds") +
ggtitle("Count(*) group-by timings")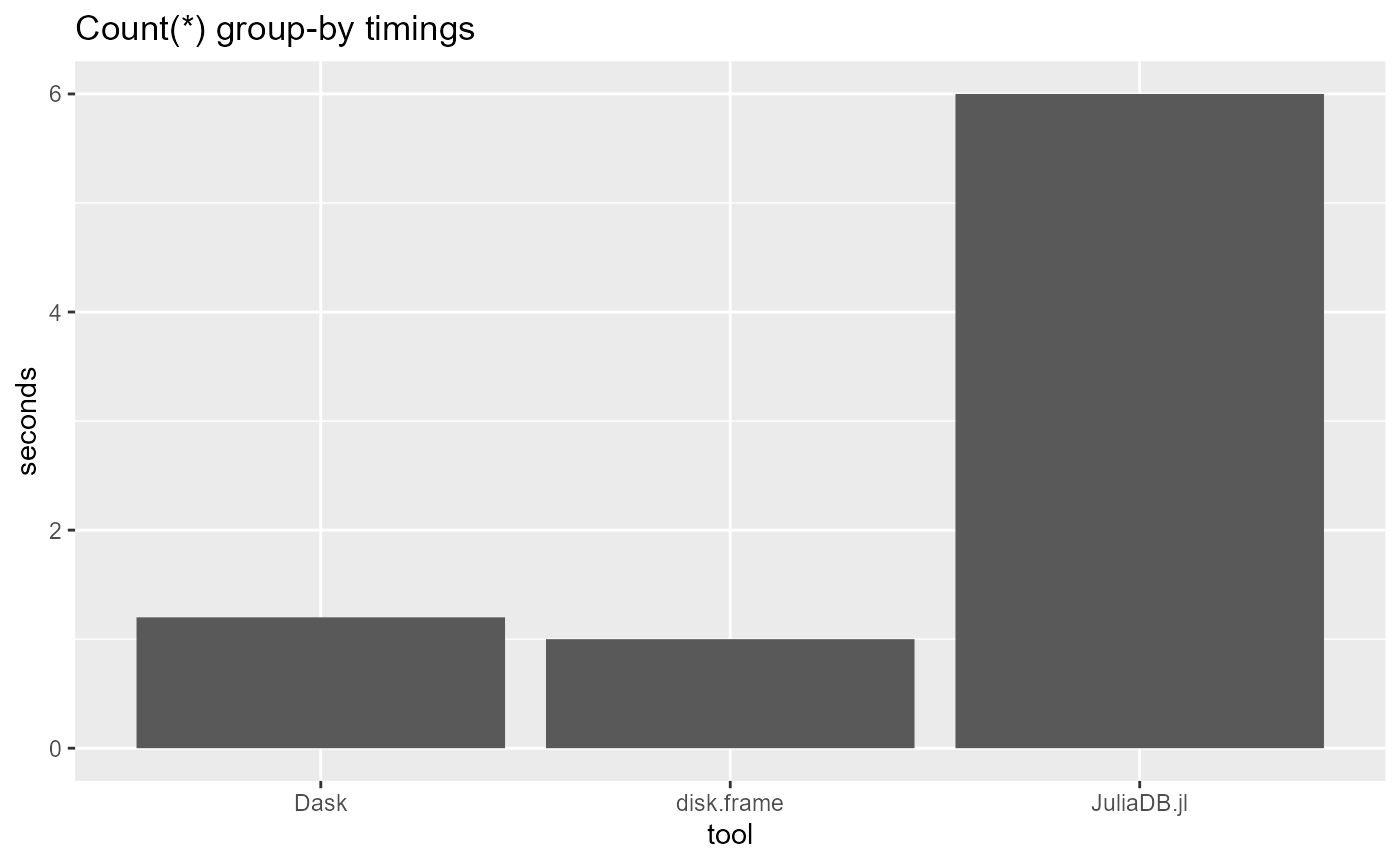
Data
The data can be obtained from Rapids.ai’s Fannie Mae Data distribution page. I have downloaded the 17 Years data which contains dat on 37 million loans with over 1.89 billions rows in Performance datasets.
To download and the data, here are some examples
For Linux users
wget http://rapidsai-data.s3-website.us-east-2.amazonaws.com/notebook-mortgage-data/mortgage_2000-2016.tgz
tar xzvg mortgage_2000-2016.tgzFor Mac users
curl http://rapidsai-data.s3-website.us-east-2.amazonaws.com/notebook-mortgage-data/mortgage_2000-2016.tgz -o mortgage_2000-2016.tgz
tar xzvg mortgage_2000-2016.tgzFor Windows users, just download the file and extract the tgz file.
Benchmark exercise: converting CSV to desired format and simple aggregation
We find the largest possible single file to give each of the tool a test run.
disk.frame
First up is disk.frame
suppressPackageStartupMessages(library(disk.frame))
system.time(setup_disk.frame()) # ~4s
#> The number of workers available for disk.frame is 6
#> user system elapsed
#> 0.17 0.01 1.06We note that there is some time needed for disk.frame to start up all the workers. Next we try to convert the largest CSV file to disk.frame format. The file to be converted is about 2.2GB in size
time_to_convert_disk.frame = system.time(df1 <- csv_to_disk.frame("c:/data/Performance_2004Q3.txt", header = FALSE))[3]
time_to_convert_disk.frame
#> elapsed
#> 28.49Now that we have converted it, we want to a count by the first column. To achieve this we use a “two-stage” aggregation strategy. Note that use keep="V1" to bring only the column V1 into RAM. This avoids the reading of other unnecessary columns and should speed-up the analysis significantly
time_to_agg_disk.frame = system.time(summ <- df1[,.N, V1, keep = "V1"][, .(N = sum(N)), V1])
#> data.table syntax for disk.frame may be moved to a separate package in the future
time_to_agg_disk.frame
#> user system elapsed
#> 0.13 0.03 9.40We can inspect the result as well.
summ
#> V1 N
#> 1: 100001458647 111
#> 2: 100004788186 95
#> 3: 100008528816 133
#> 4: 100014656651 115
#> 5: 100021529837 75
#> ---
#> 389486: 999981910757 17
#> 389487: 999982397951 104
#> 389488: 999986952752 97
#> 389489: 999990008973 162
#> 389490: 999994125744 15Another way to perform the analysis is to use dplyr syntax to perform group-by in one-stage which is:
system.time(df1 %>%
srckeep("V1") %>%
group_by(V1) %>%
summarise(N = n()) %>%
collect)
#> user system elapsed
#> 1.46 0.16 5.69However, the dplyr syntax tends to be slightly slower than using data.table syntax. This may be improved as much of the overhead is due to inefficient use of NSE.
Dask
To test Dask
import dask.dataframe as dd
from datetime import datetime
a = dd.read_csv("c:/data/Performance_2004Q3.txt", sep="|",
dtype={7: 'double', 14: 'str', 15: 'str', 16:'str'}, header = None)
a.columns = ["var" + str(i) for i in range(31)]
a.head()
startTime = datetime.now()
a.to_parquet("c:/data/p03.parquet")
print(datetime.now() - startTime) # 50 secondsand we can see that converting to Parquet takes more time than csv_to_disk.frame. Now to test Dask’s ability to aggregate a simple use-case, we can also load only column into RAM to speed up the analysis.
startTime = datetime.now()
a = dd.read_parquet("c:/data/p03.parquet", columns="var0")
aa = a.value_counts().compute()
print(datetime.now() - startTime) # 1.2The aggregation time is also longer, although in practice 1.2s. vs around 0.5s isn’t that big of a difference. We shall see how the differential changes when dealing with larger datasets in a future session.
Dask is good
A good feature of Dask is that you need not convert the data to parquet before doing the aggregation. This is a very convenient feature that is not available in disk.frame yet. For example:
startTime = datetime.now()
a = dd.read_csv("c:/data/perf/Performance_2004Q3.txt", sep="|",
dtype={7: 'double', 14: 'str', 15: 'str', 16:'str'}, header = None)
a.columns = ["var" + str(i) for i in range(31)]
startTime = datetime.now()
a.var0.value_counts().compute()
print(datetime.now() - startTime) # 50 secondsHowever this strategy is not particularly fast. In practice, you are almost always better off spending some time to convert your data to a efficient format before performing analysis. This may have a time cost, but the effort will pay off very quickly.
JuliaDB
I really like Julia but it’s a shame that JuliaDB is no where near as mature as either disk.frame nor Dask for inputting data. I have not been able to load the CSV using JuliaDB’s native methods and have resorted to using CSV.jl to read the data and convert it to JuliaDB.jl. Also, it’s difficult to figure out how to run JuliaDB from disk, and the memory usage is enormous compared to the disk.frame’s and Dask’s.
using JuliaDB, CSV, OnlineStats
path = "c:/data/perf"
# read data using CSV.jl and convert to JuliaDB
@time df = CSV.File(joinpath(path, "Performance_2004Q3.txt"), delim = '|', header = false) |> JuliaDB.table # 48Once the data has been loaded, I can aggregate as follows
using LambdaFn
@time groupby(@λ(size(_,1)), a, :Column1) # 6Unfortunately, it’s much slower than both disk.frame and Dask.
As a side note, I can use OnlineStats.jl to do aggregation (relatively) efficiently. I think OnlineStats is one of the bright spots for JuliaDB, as it has powerful online-algorithms that allows you to combine statistics by computing those statistics in chunks and combining the results from each chunk. It’s a shame that JuliaDB is not mature enough to make it shine more brightly. For an example of what it can do, see the example to compute the mean of Column6 grouped by Column1
@time groupreduce(Mean(), a, :Column1, select = :Column6)You may have noticed that we have not converted JuliaDB.jl to disk. Here we will try that
@time JuliaDB.save(a, "c:/data/.jldb") # 26sTogether with the time taken to read the data in (48s), we can say that the time to read and convert to the JuliaDB format is 48s + 28s = 76s. The issue with this conversion is that we are still not able to load only the column we need for the analysis. Random access to columns are possible with disk.frame and Dask.
Also, it’s astounding that the output file is 17GB in size and the original CSV was only 2.5GB! Loading the data takes about 9s, but uses up a lot of RAM. I think it will take time for JuliaDB to mature.
@time a = JuliaDB.load("c:/data/.jldb") # 0sConclusion
It is somewhat surprising that disk.frame is the speed king in this benchmark study, but I can’t take any of the credit as the speediness of disk.frame is due to the authors of fst, future (and parallel), and data.table. It’s also no surprise that Julia’s medium-data tool lags behind Python’s and R’s, because it’s a pattern noticed elsewhere in the data ecosystem. Julia’s niche and strength at this point is in computational problems that require lots of computation that do not necessarily involved large amounts of input data (the Celeste project appears to be an exception but I think the computational demand there dominate the data demand).
Although disk.frame is the fastest, it’s syntax is not as convenient as Dask’s. Using Dask is almost the same as using pandas. In contrast, when using disk.frame, the user needs to be aware that operations happen in chunks, and hence a “two-stage” group-by is required. However, this will be addressed in a future planned package disk.frame.db which is will allow the user to “forget” the underlying architecture is made of chunks, and just focus on higher-level data operations.